빅데이터 와 빅데이터 기술

빅데이터란?
말그대로 큰 데이터의 집합체를 의미한다. 하지만 기존에 수집하지 않았던 데이터가 지금은 각종 SNS을 통해 다양한 데이터로 기록되어 지면서 등장한 단어이다. 이러한 다량의 데이터는 기업에서 기존의 분석도구와 관리체계로는 처리를 할 수 없는 데이터들이라는것이 가장 큰 문제이다. 이러한 빅데이터가 생겨난 이유에는 페이북을 비롯한 현실과 가상이 공존하게 되면서 다양한 데이터가 입력이 발생하게 되고 이런 다량의 데이터를 처리할 수 있는 분석 도구나 관리체계가 갖추어져 있지 이러한 데이터를 활용도 못해보고 폐가되는 일들이 많아 졌다. 이러한 빅데이터를 사전에 처리할 수 있도록 데이터의 가치를 추출하고 결과를 분석하는 기술로 다양한 종류의 대규모 데이터의 생성, 수집, 분서그, 처리를 말하는것으로 다변화된 현대 사회를 더욱 정확하게 예측하여 효율적으로 작동을 하도록 하여 개인화도니 현대 사회 구성원마다 맞춤형 정보를 제공,관리, 분석하는 기술로
빅데이터 기술?
빅데이터기술은 크게 빅데이터 저장기술, 빅데이터 정제기술, 빅데이터 분석/가시화기술, 빅데이터 기반 예측 기술로 나눌 수 있다.
빅데이터 저장 기술은 이미 구글이나 애플, 야후등에 의해 요소기술로서 상당한 완성도에 도달했다. 공개소스로 Hadoop의 HDFS/BBSE, CassanDRA, mongoDB 등이 유명하다. 우리나라 ETRI의 GloryFS등과 같은 많은 솔루션이 존재한다. 빅데이터 정제기술은 빅데이터 자체가 워낙 크기 때문에 원시 데이터를 정제하기 낳고는 사용하기가 어렵다. 기계나 사람이 쏟아내는 데이터는 컴퓨터에 의해 바로 분석이 어렵기 때문이다. 즉 빅데이터의 대부분은 컴퓨터가 바로 처리할 수 없는 데이터, 컴퓨터 입장에서 보면 잘 정돈되지 않은 데이터이다. 이것을 비정형데이터(Unstructured data, Irregular Formatted Data)라고 한다. 이러한 비정형데이터를 분석,가공 가능한 형태로 만들거나 컴퓨터가 바로 처리할 수 없는 데이터를 포함한 정형적데이터를 분석 가공 가능한 형태로 만드는데 방대한 컴퓨팅 능력이 요구된다. 다시말해 정재기술은 "사람이나 기계가 만들어낸 현상을 멍청한 컴퓨터가 이해 할 수 있게 가공 하는것" 이다. 빅데이터 분석/가시화 기술은 대부분 통계학이나 데이터 마이닝이나, OLAP(Online Anaytical Processing)분야의 일이다. 빅데이터의 분석기술은 구글이 제시한 Map-Reduce 프로그래밍 모델이 보급되면서 "유의미한 시간에 대규모 데이터 정제/분석"이 가능해졌다. Map-Reduce는 빅데이터를 나누어 저장하고 있는 수백, 수천대의 서버 각각에서 자기가 저장하고 있는 데이터에 대한 정제/분석을 할 수 있는대로 해서 그 결과값을 모아 최종 정제/분석결과를 내는 방법이다. 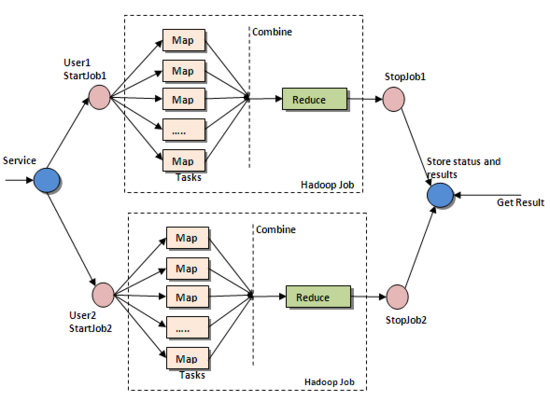
빅데이터기반 예측기술은 모델 단순화나 샘플링 기반의 통계적 예측에 의존하지 않고 고도의 수학적 기반과 전문성을 요구하고 있으며, 네트워크 이론아니 신경망 이론에 가깝다고 볼 수 있다. 수학적 기호나 표상을 사용하는 모델링 자체가 없는 경우도 많고 SVD(Singular Value Decomposition)나 LSA(Latent Semantic Anaysis)처럼 왜 되는지는 모르지만 자꾸 돌리면 잘 맞게되는 경우가 많다. 즉 이말은 누가 빨리 시작해서 많이 해봤느냐가 중요하고 관련기술이나 솔루션도 거의 없다.